

要求:
http://sports.163.com/zc/
提取网站中全部新闻标题名称,标题路由地址,标签,时间,评论数保存到文档中
案例分析:
(1)请求部分
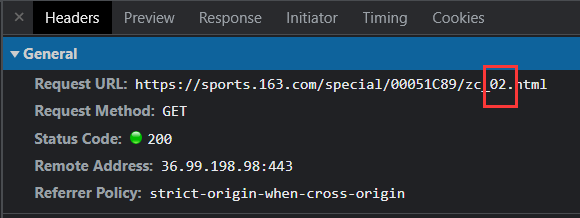
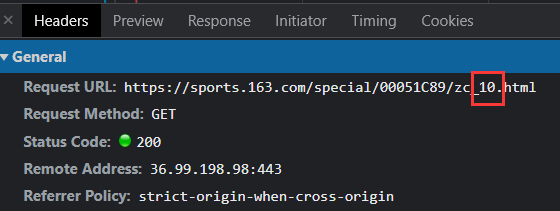
查看网站信息可知,该网站的请求地址会随着页面的变化而发生变化。如果是第一页,则可以直接引用网址,如果是单位数的页面,可以直接改变个位数页,以此类推...在这里,我们就可以对路由地址进行if分类判断
(2)解析部分
首先取出信息所在的节点,里面就包含了每页中的所有新闻信息的列表,如果用正则方法爬取,代码如下:
如果用xpath方法爬取,代码如下:
当然,也可以用beautifulsoup方法,方法众多,可以任意选用
当我们解析出列表标签后,我们就可以进行深入解析了
正则方法:大家要熟练掌握re.search()和re.findall()为主的正则匹配方法
xpath方法:
解析完数据之后,就要进行数据的保存,可以保存到数据库中,也可以报道到文本txt中
保存到文档:
保存到数据库:
当我们爬取的数据量比较大时,我们就需要考虑项目的稳定性了。比如我们可以加time.sleep(),也可以写逻辑做容错处理,比如一些简单的处理:
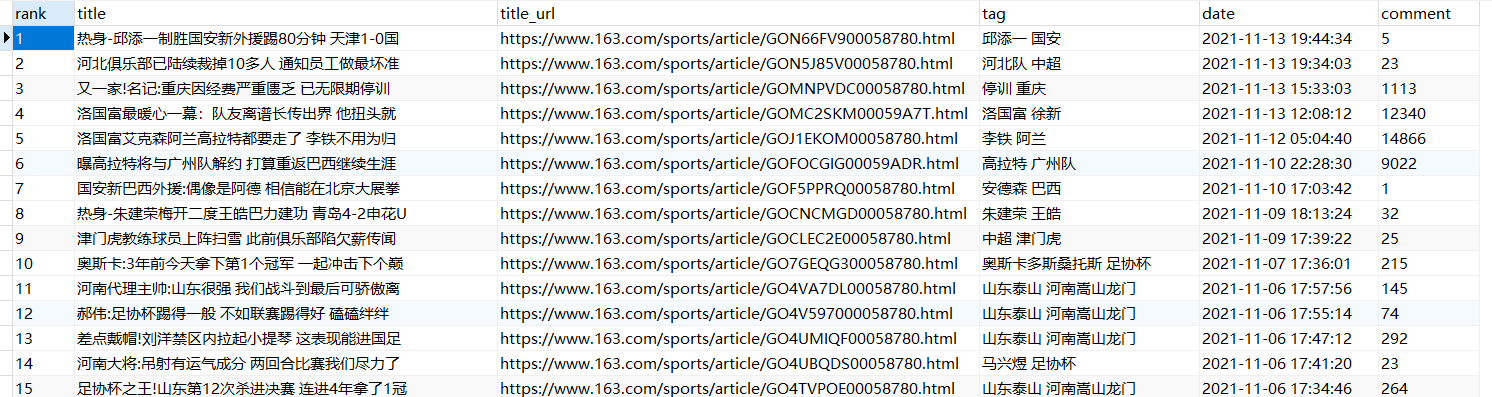
结果展示:

保存到文本:

保存到数据库:
喜欢小编的关注、点赞走一波呦,后期会不定期分享更多Python爬虫相关知识


文章声明:以上内容(如有图片或视频在内)除非注明,否则均为欧洲杯赛程表|欧洲杯直播|CCTV5在线直播原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://6y2w302.com/post/1424.html
还没有评论,来说两句吧...